
- 개요

일평균기온은 당연히 여름에 높고, 겨울에는 낮습니다.
적당히 여름에 높게, 겨울에 낮게 온도를 예측하면 성능이 나올거고, 선형회귀모델은 필연적으로 이런 경향을 학습하여 기본적인 성능이 높을 수밖에 없습니다.
그렇다면 계절성을 제거하면 예측 능력이 어떻게 될까요?
- 함수화 작업
계절성 제거 이전에 기존 코드를 함수로 만들고자 합니다.
같은 코드를 중복으로 사용할 일이 많아 다시 모든 코드를 넣기에는 글이 너무 길어집니다.
긴 코드는 그냥 함수로 만들어서 다음 포스트부터는 함수만 적겠습니다.
"""
read_ASOS108(): 서울 ASOS 자료를 pandas DataFrame 형태로 읽음
"""
import pandas as pd
import numpy as np
import os
def read_ASOS108():
inpath = "../data/ASOS108"
fnlist = os.listdir(inpath)
dfs = []
for fn in fnlist:
df = pd.read_csv(os.path.join(inpath, fn), encoding='cp949')
dfs.append(df)
return pd.concat(dfs)
"""
process_cols(df, use_cols): 입력자료로 사용할 열 추출 및 생성, 자료의 전처리 단계
"""
def process_cols(df, use_cols):
df['일강수량(mm)'] = df['일강수량(mm)'].fillna(0)
df1 = df[use_cols].dropna()
df1['datetime'] = pd.to_datetime(df1['일시'])
df1['year'] = df1['datetime'].dt.year
df1['month'] = df1['datetime'].dt.month
df1['day'] = df1['datetime'].dt.day
return df1.sort_values(by='datetime')
"""
split_data(df, date): date를 기준으로 앞은 학습기간, 뒤는 테스트기간으로 분류, 입력자료, 예측값 분류
"""
def split_data(df, date):
datetime = df['datetime'][df['datetime'] >= date]
train_df = df[df['datetime'] < date].drop('datetime', axis=1)
test_df = df[df['datetime'] >= date].drop('datetime', axis=1)
train_X = train_df.drop('Y', axis=1)
train_y = train_df['Y']
test_X = test_df.drop('Y', axis=1)
test_y = test_df['Y']
return train_X, train_y, test_X, test_y, datetime
"""
do_prediction(train_X, train_y, test_X, test_y): 학습기간으로 모델 학습 후 테스트기간 예측을 수행, 실제값과 예측값 간의 RMSE, 상관계수 반환
"""
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from scipy.stats import pearsonr
def do_prediction(train_X, train_y, test_X, test_y):
model = LinearRegression()
model.fit(train_X, train_y)
predictions = model.predict(test_X)
rmse = np.sqrt(mean_squared_error(test_y, predictions))
corr, _ = pearsonr(test_y, predictions)
return predictions, rmse, corr
"""
실제값과 예측값을 시각화
draw_scatter(test_y, predictions, rmse, corr): 산포도
draw_ts(test_y, predictions, datetime, rmse, corr): 시계열
"""
import plotly.express as px
import plotly.graph_objects as go
import matplotlib.pyplot as plt
def draw_scatter(test_y, predictions, rmse, corr):
fig = px.scatter(x=test_y, y=predictions, labels={'x': 'Actual', 'y': 'Predicted'},
title=f'Real vs Predicted (RMSE: {rmse:.2f}, Corr: {corr:.2f})')
fig.update_layout(
xaxis=dict(scaleanchor="y", range=[-15, 15]),
yaxis=dict(scaleanchor="x", range=[-15, 15]),
width = 600,
height = 600
)
fig.update_traces(marker=dict(size=2, opacity=0.6, line=dict(width=1, color='DarkSlateGrey')), selector=dict(mode='markers'))
fig.show()
def draw_ts(test_y, predictions, datetime, rmse, corr):
fig = go.Figure()
fig.add_trace(go.Scatter(x=datetime, y=test_y, mode='lines', name='Actual', line=dict(color='blue')))
fig.add_trace(go.Scatter(x=datetime, y=predictions, mode='lines', name='Predicted', line=dict(color='red')))
fig.update_layout(
title=f'Real vs Predicted (RMSE: {rmse:.2f}, Corr: {corr:.2f})'
)
fig.show()
- 계절성 제거 함수 작성
개요에서 당연히 여름철 기온은 높고, 겨울철 기온은 낮다고 했습니다. 이러한 계절적 변화를 제거하는 것을 "계절성을 제거한다"라고 이해하시면 됩니다.
계절성을 지우는 방법은 분석기간에 대해 각 월과 일의 평균값을 기존값에서 제거하는 것입니다.
엄밀히는 미래는 알 수 없기 때문에 학습기간만의 계절성을 제거하는 것이 맞을 것 같습니다만, 전 그냥 모든 기간의 계절성을 제거했습니다.
자세한 설명은 함수의 주석으로 적습니다.
def remove_seasonal_cycle(df, use_cols):
"""
'day_of_year'열은 월-일 형식으로 나중에 groupby 방법으로 같은 값을 갖는 경우 평균을 하기 위해 쓰입니다.
이러면 groupby까지 마치고 나면 01-01은 1월 1일의 평균값, 01-02는 1월 2일의 평균값으로
1월 1일부터 12월 31일까지의 seasonal cycle을 구한것이고 각각의 값을 보통 그 날의 평년값이라고 부릅니다.
"""
df['day_of_year'] = df['datetime'].dt.strftime('%m-%d') # MM-DD 형식
for col in use_cols[1:]: # '일시' 제외
seasonal_cycle = df.groupby('day_of_year')[col].mean()
"""
2월 29일 처리: 2월 28일과 3월 1일값을 2월 29일의 평년값으로 선언했습니다.
이렇게 해도 큰 문제는 없지만 연구 목적으로 코드를 작성하시는 분은 좀 더 정교한 방법을 쓰세요.
"""
if '02-29' in seasonal_cycle:
if '02-28' in seasonal_cycle and '03-01' in seasonal_cycle:
seasonal_cycle['02-29'] = (seasonal_cycle['02-28'] + seasonal_cycle['03-01']) / 2
df[f'{col}_seasonal_cycle'] = df['day_of_year'].map(seasonal_cycle)
df[f'{col}_detrended'] = df[col] - df[f'{col}_seasonal_cycle']
"""
day_of_year와 seasonal cycle은 입력자료로 쓰이지 않으므로 제거하고 return합니다.
"""
return df.drop(columns=['day_of_year'] + [f'{col}_seasonal_cycle' for col in use_cols[1:]])
- 하루 뒤 서울 일평균기온 예측(계절성 제거)
저번에는 서울 ASOS 자료에서 20여개 종류의 변수를 추출했지만 이번에는 더 적은 변수만 추출합니다.
제 주관적인 판단하에 계절성을 제거하여 입력자료로 쓰기에 애매한 변수는 뺏습니다.
df_raw = read_ASOS108()
use_cols = ['일시', '평균기온(°C)', '일강수량(mm)', '평균 풍속(m/s)',
'평균 이슬점온도(°C)', '평균 상대습도(%)',
'평균 현지기압(hPa)', '평균 전운량(1/10)', '합계 일사량(MJ/m2)']
df_raw1 = process_cols(df_raw, use_cols)
df_raw1 = remove_seasonal_cycle(df_raw1, use_cols)
target = '평균기온(°C)_detrended'
df_raw1['Y'] = df_raw1[target].shift(-1)
df_raw1 = df_raw1.iloc[:-1]
"""
detrend하지 않은 열은 제거합니다.
"""
use_cols_detrend = df_raw1.columns
use_cols_detrend = [ col for col in use_cols_detrend if col not in use_cols]
df_raw1 = df_raw1[use_cols_detrend]
train_X, train_y, test_X, test_y, datetime = split_data(df_raw1, '2022-01-01')
predictions, rmse, corr = do_prediction(train_X, train_y, test_X, test_y)
draw_scatter(predictions, test_y, rmse, corr)draw_ts(test_y, predictions, datetime, rmse, corr)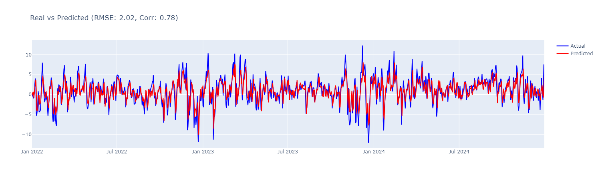
상관계수가 0.78로 여전히 높긴한데 저번 포스트보다 성능이 많이 감소했습니다.
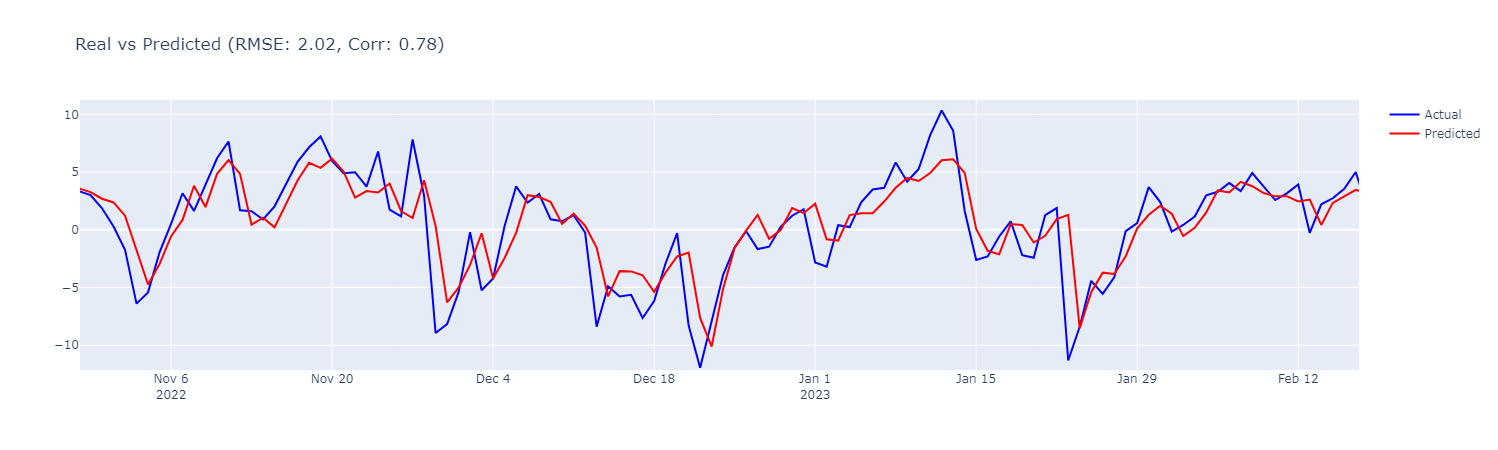
확대해보면 여전히 하루 전날 값을 그대로 예측하는 경향이 있습니다.
실제로 예측값의 시간을 하루 뒤로 옮겨서 실제값과의 상관계수를 구하면 0.9507이 나옵니다.
- 결론 및 다음 방향
계절성을 제거해도 여전히 전 날 평균기온을 예측한다.
입력자료로 서울 ASOS 자료 이외에 다른 자료도 넣어봐야겠다.
'프로젝트 > 기계학습 기반 서울 기온 예측' 카테고리의 다른 글
| [서울기온예측][XGboost 2] 서울 ASOS 자료 기반 기온 예측 (0) | 2025.02.25 |
|---|---|
| [서울기온예측][XGboost 1] 의사결정나무, XGboost란? (0) | 2025.02.20 |
| [서울기온예측][다중선형회귀모델 3] 예측 변수와 입력 변수 간 선형상관계수 확인 (0) | 2025.02.17 |
| [서울기온예측][다중선형회귀모델 1] 서울 ASOS 자료만 사용한 기온 예측 (0) | 2025.02.10 |
| [서울기온예측] 프롤로그 (1) | 2025.02.06 |