- 개요

가장 간단한 예측 모델인 다중선형회귀모델로 하루 뒤 서울 일평균기온을 예측해보겠습니다.
선형회귀모델에서 먼저 y(예측) = a*x(입력자료) + b, 선형함수의 a와 b를 구합니다.
실제값과 예측값 간 오차를 최대한 작게 만드는 a, b값을 구합니다.
그럼 입력자료를 넣으면 예측값이 나오는 것이죠.
이 때 입력자료가 1개뿐이라면 y = a*x + b로 충분하지만 여러개라면 y = a1 * x1 + a2 * x2 ....처럼 다중선형함수로 예측하여 실제값과 예측값 간 오차를 최대한 작게 만드는 a1, a2..., b를 구합니다.
이번 포스트에서는 모델의 입력자료로 서울 ASOS 자료만 씁니다.
이것저것 다른 방법을 사용해본 뒤 서울 ASOS 자료말고도 다른 자료를 사용해볼 계획입니다.
pandas, numpy, matplotlib, seaborn, scipy, sklearn, plotly 라이브러리를 사용했습니다.
- 자료 수집 및 전처리
기상자료개방포털의 서울 ASOS 일단위 자료 다운로드 받습니다.
일자료의 경우 한 번에 10년씩 받을 수 있고, 저는 1995~2024년까지 총 30년치의 3개 파일을 다운로드 받았습니다.
"""
ASOS 자료 읽기
"""
import pandas as pd
import numpy as np
import os
inpath = "../data/ASOS108" # 30년치의 3개 파일을 한 폴더에 저장했습니다.
fnlist = os.listdir(inpath)
dfs = []
for fn in fnlist:
df = pd.read_csv(os.path.join(inpath, fn), encoding='cp949')
dfs.append(df)
df_raw = pd.concat(dfs)
ASOS 자료의 열은 60개가 넘습니다. 숫자가 아닌 글자자료가 있다거나 결측값이 너무 많은 열이 있습니다.
제 마음대로 적당히 결측값이 적은 22개의 열을 선정하여 추출했습니다.
이 열은 선형회귀모델의 입력 자료로 사용될 것이며, 시간정보는 연, 월, 일로 입력하고 싶으므로 year, month, day열을 추가했습니다.
"""
서울기온 예측 모델의 입력 자료를 만들기 위한 전처리
입력자료로 쓰일 열만 추출, year, month, day 열 생성
"""
use_col = ['일시', '평균기온(°C)', '최저기온(°C)', '최저기온 시각(hhmi)', '최고기온(°C)', '최고기온 시각(hhmi)', '일강수량(mm)', '평균 풍속(m/s)',
'최다풍향(16방위)', '평균 이슬점온도(°C)', '최소 상대습도(%)', '최소 상대습도 시각(hhmi)', '평균 상대습도(%)',
'평균 증기압(hPa)', '평균 현지기압(hPa)', '최고 해면기압(hPa)', '최고 해면기압 시각(hhmi)', '최저 해면기압(hPa)', '최저 해면기압 시각(hhmi)',
'평균 해면기압(hPa)', '평균 전운량(1/10)', '합계 일사량(MJ/m2)']
df_raw['일강수량(mm)'] = df_raw['일강수량(mm)'].fillna(0) # 강수량의 결측은 0 mm 왔다는 뜻
df_raw1 = df_raw[use_col].dropna() # 결측 제거
df_raw1['datetime'] = pd.to_datetime(df_raw1['일시'])
df_raw1['year'] = df_raw1['datetime'].dt.year
df_raw1['month'] = df_raw1['datetime'].dt.month
df_raw1['day'] = df_raw1['datetime'].dt.day
# 시간순서와 파일이름 순서가 일치하지 않아 시간순으로 정렬합니다.
# 1995년부터 시간 순으로 파일부터 읽으면 시간순 정렬은 필요없습니다.
df_raw1 = df_raw1.sort_values(by='datetime')
다음으로 하루 뒤 평균기온 열을 추가합시다.
오늘 얻은 ASOS 관측 자료로 내일 평균기온을 예측하는 것이 목표이므로 2025년 2월 10일 행이라면 2025년 2월 11일의 평균기온이 target 변수로 있어야 합니다.
target = '평균기온(°C)'
df_raw1['Y'] = df_raw1[target].shift(-1)
df_raw1 = df_raw1.iloc[:-1] # 1행을 당겨서 저장하는 것이므로 Y열의 마지막 행은 NaN값
- 학습, 테스트 기간으로 데이터 분류
선형회귀모델에서는 학습기간으로 학습을 수행하고, 테스트기간으로 모델의 예측 성능을 평가합니다.
보통 학습은 전체기간의 90%, 테스트는 10%로 잡습니다.
총 30년 자료이므로 전 2022~2024년의 3년을 테스트 기간으로 설정하려고 2022년 1월 1일을 기준으로 학습기간, 테스트기간을 나누었습니다.
학습기간은 9828일, 테스트기간은 1088일로 적당히 9:1 비율로 나뉩니다.
"""
split_data()함수는 date를 기준으로 앞기간은 학습기간, 뒷기간은 테스트기간으로 나누어줍니다.
train은 학습 기간
test는 테스트 기간
X는 예측하기 위한 입력자료
y는 예측할 변수인 하루 뒤 평균기온입니다.
datetime은 입력 변수가 아니어서 제거(drop)
그림 그릴 때 xticklabel로 쓰려고 datetime을 따로 return합니다.
"""
def split_data(df, date):
datetime = df['datetime'][df['datetime'] >= date]
train_df = df[df['datetime'] < date].drop('datetime', axis=1)
test_df = df[df['datetime'] >= date].drop('datetime', axis=1)
train_X = train_df.drop('Y', axis=1) # 예측할 변수를 입력 자료에서 빼야함
train_y = train_df['Y']
test_X = test_df.drop('Y', axis=1)
test_y = test_df['Y']
return train_X, train_y, test_X, test_y, datetime
df = df_raw1.drop(['일시'], axis=1)
train_X, train_y, test_X, test_y, datetime = split_data(df, '2022-01-01')
- 다중선형회귀모델 예측
선형회귀모델을 사용하기위해 sklearn의 LinearRegression 함수를 사용합니다.
예측결과를 확인하기 위해 x축은 테스트기간의 실제값(평균기온 관측), y축은 테스트기간에 선형회귀모델의 예측값으로 산포도를 그렸습니다.
import plotly.express as px
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from scipy.stats import pearsonr
model = LinearRegression()
model.fit(train_X, train_y)
predictions = model.predict(test_X)
rmse = np.sqrt(mean_squared_error(test_y, predictions))
corr, _ = pearsonr(test_y, predictions)
fig = px.scatter(x=test_y, y=predictions, labels={'x': 'Actual', 'y': 'Predicted'},
title=f'Real vs Predicted (RMSE: {rmse:.2f}, Corr: {corr:.2f})')
fig.update_layout(
xaxis=dict(scaleanchor="y", range=[-15, 35]),
yaxis=dict(scaleanchor="x", range=[-15, 35]),
width = 600,
height = 600
)
fig.update_traces(marker=dict(size=2, opacity=0.6, line=dict(width=1, color='DarkSlateGrey')), selector=dict(mode='markers'))
fig.show()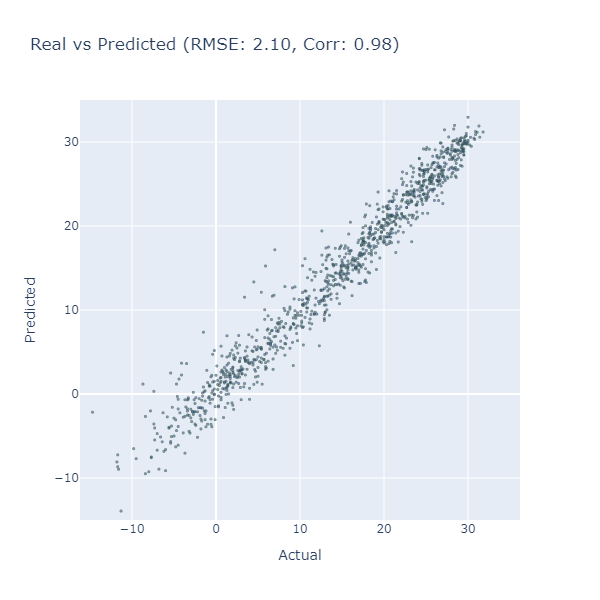
RMSE는 2.10, 선형상관계수는 0.98로 숫자만 보면 훌륭합니다.
다음으로 시계열도 확인해봅시다. 파란색이 실제값 빨간색이 예측값입니다.
"""
산포도를 그릴 때 선언한 변수를 활용합니다.
"""
import plotly.graph_objects as go
fig = go.Figure()
# 실제값과 예측값 시각화
fig.add_trace(go.Scatter(x=datetime, y=test_y, mode='lines', name='Actual', line=dict(color='blue')))
fig.add_trace(go.Scatter(x=datetime, y=predictions, mode='lines', name='Predicted', line=dict(color='red')))
fig.update_layout(
title=f'Real vs Predicted (RMSE: {rmse:.2f}, Corr: {corr:.2f})'
)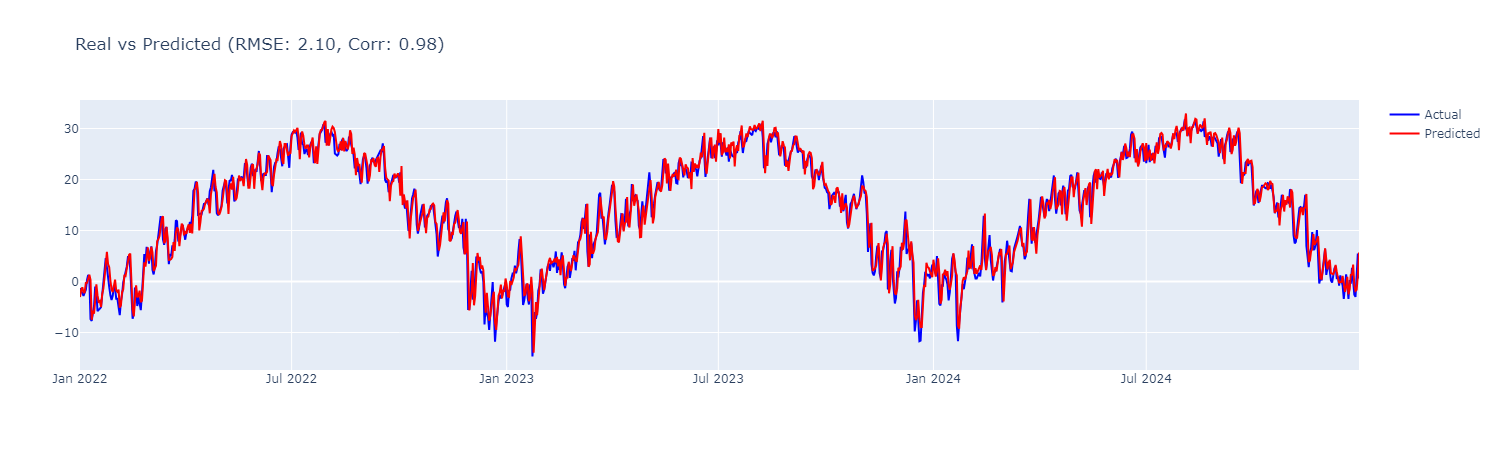
상관계수가 0.98이라 그런지 거의 똑같은 시계열입니다.
하지만 자세히 보면 문제를 발견할 수 있습니다.
(ipynb 확장자에서 plotly로 그린 그림은 자유롭게 확대/축소가 가능합니다. 전 vscode로 작업했습니다.)

파란선을 오른쪽으로 움직이면 빨간선과 아주 비슷하지 않나요?
선형회귀모델은 오늘의 평균기온을 다음 날의 평균 기온으로 예측하는 경향이 있습니다.
실제로 예측값을 하루 당겨서 실제값 간 상관계수를 확인해보니 0.9947이 나옵니다.
- 결론
수치만 보면 선형회귀모델은 다음 날 평균기온을 아주 훌륭히 예측하고 있다.
실제로는 당일 평균기온을 다음 날 평균기온이라고 예측하고 있어 성능이 나쁜 것이다.
평균기온은 여름철에 높고, 겨울철에 낮은 계절변동성이 심하여 이를 예측하는 것만으로도 성능이 나오는 것 같습니다.
- 다음 방향
반드시 하는 것도 아니고, 다른 걸 할 수도 있음
1. 계절변동성을 제거하고 평균기온 예측해보기
순수 일변동은 어느 정도 예측하는지? 전날을 그대로 예측하는지 궁금함
2. 다양한 입력자료를 넣어보기
전날값을 그대로 예측하기 문제를 해결하기 위해서는 다양한 입력자료를 넣으라는 인터넷 글을 보았음. ASOS 47108 관측소자료 이외의 다른 자료를 입력자료로 넣기
'프로젝트 > 기계학습 기반 서울 기온 예측' 카테고리의 다른 글
| [서울기온예측][XGboost 2] 서울 ASOS 자료 기반 기온 예측 (0) | 2025.02.25 |
|---|---|
| [서울기온예측][XGboost 1] 의사결정나무, XGboost란? (0) | 2025.02.20 |
| [서울기온예측][다중선형회귀모델 3] 예측 변수와 입력 변수 간 선형상관계수 확인 (0) | 2025.02.17 |
| [서울기온예측][다중선형회귀모델 2] 코드 함수화, 서울 ASOS 자료의 계절성 제거 (0) | 2025.02.11 |
| [서울기온예측] 프롤로그 (1) | 2025.02.06 |