[python][지하철 승하차 자료] 회사원은 언제 연차를 낼까? 2. 연차를 내는 시기
- 요약


- 개요
저번 포스트에서 출근시간/퇴근시간에 지하철 인원수가 많으면 연차를 쓴 사람이 적다라는 가정을 하고 관련 수치를 일(daily) 단위로 정리했습니다.
이 다음은 무엇을 해야할까요?
아마 이 질문에 대답하기 어려울 것인데 그 이유는 제가 질문을 막연하게 했기 때문입니다.
저는 단순한 호기심에 분석하는 것이고 구체적인 목표가 없거든요.
회사에 다니다보면 막연하게 이런 느낌의 업무를 맡는 분도 있을 것 같은데 이럴 땐 쉬운 것부터 하면 됩니다.
예를 들어 잘 쓴 글에서는 독자가 이해하기 쉬운 내용부터 어려운 내용의 순서로 나옵니다.
분석도 이처럼 쉬운 것부터 하면 되는데요.
여기서 쉽다는 건 독자가 이해하기 쉽다기보다 "기술적으로 쉽게 분석할 수 있으며 내가 이해가 쉬운 것을 의미합니다(보통 내가 이해하기 쉬우면 남도 쉬움)."
그러면 숲부터 파악을 하고 나무를 파악하는 식으로 분석을 하게 됩니다.
이 분석에서 숲은 어느 기간에 연차를 많이 쓰냐? 그럼 좀 더 디테일하게 나무는 어느 시기의 요일에 연차를 많이 쓰냐?처럼 숲에서 나무로 갈수록 질문이 점점 구체적이고 자세해집니다.
쉬운 것부터 하자고 했으니 전체기간 중 언제 사람들이 연차를 많이 쓰는 지 알아보겠습니다.
- 전처리 작업: 주말과 주일의 분리
주말과 주일을 분리해서 분석하겠습니다.
datetime 형식의 열에 .dt.weekday를 뒤에 붙이면 0~6값이 반환됩니다.
값은 0~6까지로 월요일부터 일요일까지 값입니다.
# 데이터 읽기
import pandas as pd
import os
inpath = './data'
files = ['서울교통공사_역별 일별 시간대별 승하차인원 정보_20221231.csv',
'서울교통공사_역별 일별 시간대별 승하차인원 정보_20231031.csv',
'서울교통공사_역별 일별 시간대별 승하차인원 정보_23.11_24.01.csv',
'서울교통공사_역별 일별 시간대별 승하차인원(24.2~24.5).csv']
dfs = []
col_names = ['연번', '날짜', '호선', '역번호', '역명', '구분', '06시 이전', '06시-07시', '07시-08시',
'08시-09시', '09시-10시', '10시-11시', '11시-12시', '12시-13시', '13시-14시',
'14시-15시', '15시-16시', '16시-17시', '17시-18시', '18시-19시', '19시-20시',
'20시-21시', '21시-22시', '22시-23시', '23시-24시', '24시 이후']
for file in files:
df = pd.read_csv(os.path.join(inpath, file), encoding='cp949')
df.rename(columns=dict(zip(df.columns, col_names)), inplace=True)
dfs.append(df)
df = pd.concat(dfs)
use_col = ['날짜', '구분', '06시 이전', '06시-07시', '07시-08시',
'08시-09시', '09시-10시', '10시-11시', '11시-12시', '12시-13시', '13시-14시',
'14시-15시', '15시-16시', '16시-17시', '17시-18시', '18시-19시', '19시-20시',
'20시-21시', '21시-22시', '22시-23시', '23시-24시', '24시 이후']
df_gasan = df[use_col][df['역명'] == '가산디지털단지'].copy()
df_gasan['출근인원수'] = df_gasan[['07시-08시','08시-09시', '09시-10시']].sum(axis=1).copy()
df_gasan['퇴근인원수'] = df_gasan[['17시-18시','18시-19시', '19시-20시']].sum(axis=1).copy()
df_commute = pd.DataFrame(
{'datetime': pd.to_datetime(df_gasan['날짜'][df_gasan['구분']=='승차'].tolist()),
'출근인원수': df_gasan['출근인원수'][df_gasan['구분']=='하차'].tolist(),
'퇴근인원수': df_gasan['퇴근인원수'][df_gasan['구분']=='승차'].tolist(),
}
)
df_commute = df_commute[(df_commute['datetime'] >= '2022-05-01') &
((df_commute['datetime'] < '2023-07-01') |
(df_commute['datetime'] >= '2023-10-01'))]
"""
weekday를 사용하면 0~6까지 값이 반환
0: 월, 1: 화, 2: 수, 3: 목, 4: 금, 5: 토, 6: 일
"""
df_commute['weekday'] = df_commute['datetime'].dt.weekday
- 주일 출근인원 시계열 분석
이제부터는 출근인원을 위주로 분석하겠습니다.
출퇴근을 하지 않는 사람은 늦게 일어날 것이기에 퇴근시간에 영향을 더 많이 끼친다고 생각하기 때문입니다.
그리고 제 경험상 보통 출장이 있어도 일단 출근은 하고 출장을 가는 경우가 많아 출근인원수가 실제 회사에 온 사람수와 더 비슷할겁니다. 실제로 출근인원수가 퇴근인원수보다 많습니다.
출근인원이 많으면 연차를 적게 쓴거고, 적으면 연차를 많이 쓴 것이라 해석하면 됩니다.
2023년 7월~9월은 자료가 없는 것이니 그림을 볼 때 주의하시길 바랍니다.
1. 주일 출근인원 시계열 그리기
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.font_manager as fm
df_days = df_commute[df_commute['weekday']<5]
df_ends = df_commute[df_commute['weekday']>=5]
fn_font = 'NanumSquareB.ttf'
fontprop = fm.FontProperties(fname=fn_font, size=10)
def draw_ts(df):
""" 시계열 그리는 함수"""
fig, ax = plt.subplots(figsize=(20, 4))
# Seaborn barplot 사용
sns.barplot(x=df['datetime'], y=df['출근인원수'], color='steelblue', edgecolor='black', alpha=0.8, ax=ax)
# x축 라벨 설정, 월요일만 x축에 표기
xticks = np.where(df['weekday'] == 0)[0]
ax.set_xticks(xticks)
ax.set_xticklabels(df['datetime'].dt.strftime('%Y-%m-%d').iloc[xticks], rotation=90, ha='center')
ax.set_title("출근 인원수 변화", fontproperties=fontprop, fontsize=14)
ax.set_ylabel("출근 인원수", fontproperties=fontprop, fontsize=12)
ax.set_xlabel("날짜", fontproperties=fontprop, fontsize=12)
plt.show()
draw_ts(df_days)
주일의 출근인원수를 시계열로 그렸는데 중간에 값이 갑자기 확 낮아집니다.
이는 월요일~금요일에 공휴일이 있기 때문입니다.
공휴일도 제거합시다.
"""
공휴일을 reddays 리스트에 저장하고 df_days에서 해당 날짜를 제거합니다.
"""
reddays = ['2022-05-01', '2022-05-05', '2022-06-01', '2022-06-06', '2022-08-15',
'2022-09-09', '2022-09-12', '2022-10-03', '2022-10-10',
'2023-01-23', '2023-01-24', '2023-03-01', '2023-05-01', '2023-05-05',
'2023-05-29', '2023-06-06', '2023-10-02', '2023-10-03',
'2023-10-09', '2023-12-25', '2024-01-01', '2024-02-09',
'2024-02-12', '2024-03-01', '2024-04-10', '2024-05-01', '2024-05-06',
'2024-05-15']
df_reddays = pd.to_datetime(reddays)
"""
df_days['datetime'].isin(df_reddays)는
df_days의 행별로 공휴일이 있으면 True, 아니면 False를 반환
이 앞에 ~를 붙이면 True, False가 바뀌므로 공휴일이 없는 날이 True
"""
df_days_wo_red = df_days[~df_days['datetime'].isin(df_reddays)]
draw_ts(df_days_wo_red)
2. 주일 출근인원 시계열 해석
공휴일을 제거해도 출근인원이 적어지는 시기가 있습니다.
이 때가 바로 연차를 많이 쓰는 시기겠죠.
날짜를 보면서 연차를 많이 이유를 해석해봅시다.

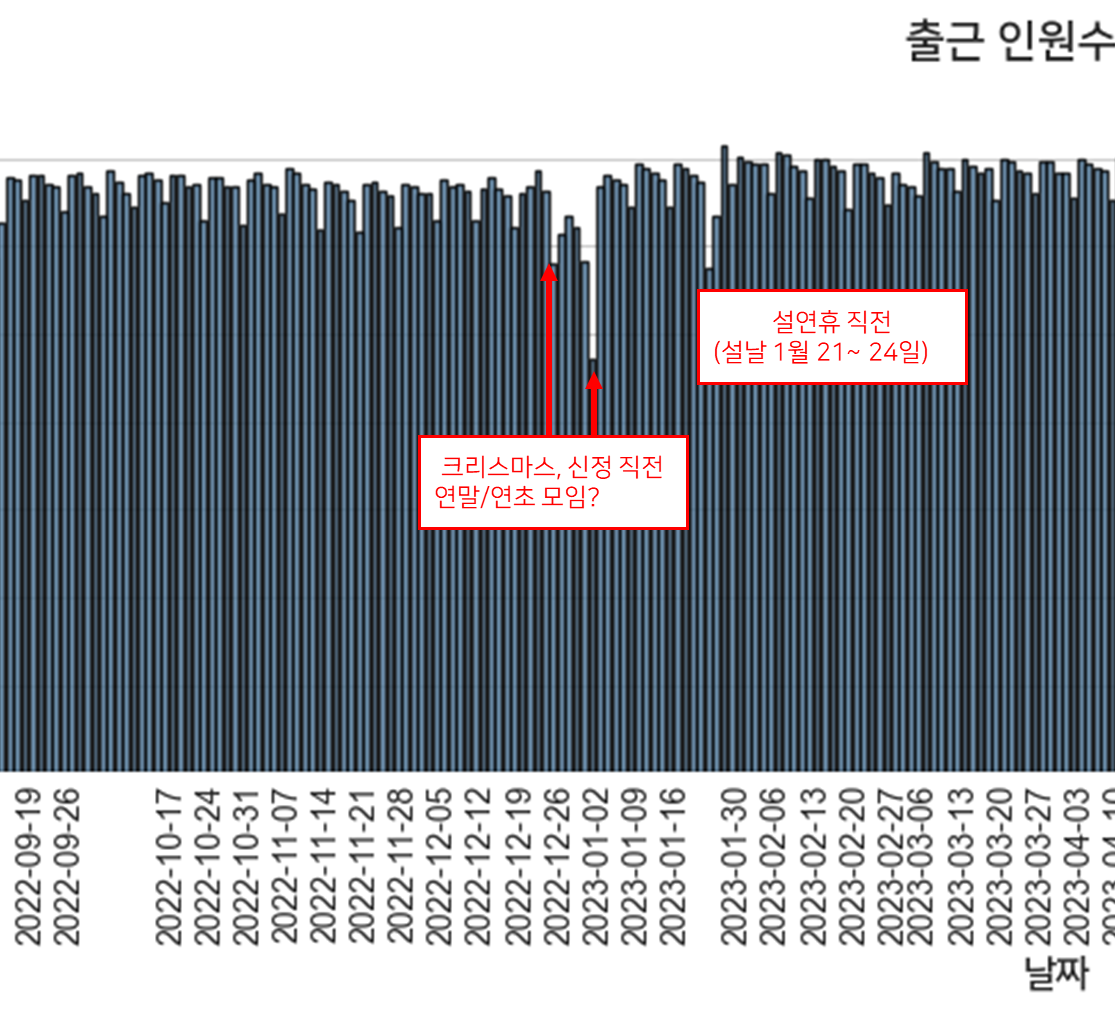

제가 보기에는 직장인은
- 휴일과 휴일 사이에 있는 평일
- 설날, 추석 연휴 직전
- 여름 휴가
- 크리스마스, 신정의 연말연초 기간
이 기간에 연차를 많이 쓰는 것 같습니다.