[서울기온예측][XGboost 2] 서울 ASOS 자료 기반 기온 예측
- 개요
선형회귀모델로 하루 뒤 서울 평균기온을 예측해보았으니 이젠 XGboost로 예측해 볼 차례입니다.
선형회귀모델에서는 입력변수도 바꿔보고 계절성도 없애보는 내용을 각각 하나의 포스트로 작성했지만 XGboost에서는 포스트 하나에서 모든 결과를 확인하겠습니다.
모든 모델은 하루 뒤 서울 평균기온을 예측합니다.
- XGboost 코드
XGboost의 입력 데이터셋은 선형회귀모델의 입력 데이터셋과 같습니다.
데이터를 읽거나 계절성을 제거하는 코드는 선형회귀모델 포스트에 있으니 이번에는 따로 다루지는 않겠습니다.
XGboost는 random_state, n_estimator, max_depth와 같은 파라미터 값에 따라 성능이 달라지지만 저는 일단 하나만 사용합니다.
최고의 성능을 얻고 싶으면 여러 파라미터의 조합을 사용해서 성능을 일일히 확인해야 합니다.
from xgboost import XGBRegressor
from sklearn.metrics import mean_squared_error
from scipy.stats import pearsonr
model = XGBRegressor(random_state = 0, n_estimators = 64, max_depth = 8)
model.fit(train_X, train_y)
predictions = model.predict(test_X)
rmse = np.sqrt(mean_squared_error(test_y, predictions))
corr, _ = pearsonr(test_y, predictions)
# draw_scatter(predictions, test_y, rmse, corr)
draw_ts(test_y , predictions, datetime, rmse, corr)
print(corr, rmse)
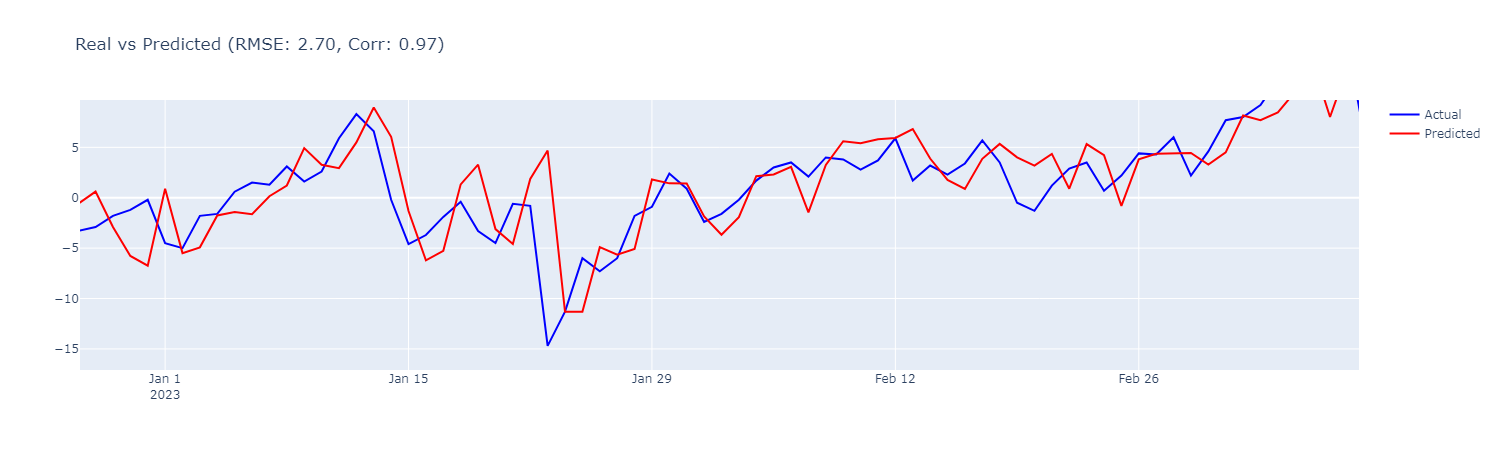
- XGboost, 입력자료: 평균 기온
상관계수(corr)와 RMSE만 비교할 계획이지만 먼저 예측 결과를 확대해서 살펴보고자 합니다.
선형회귀모델 때와 마찬가지로 오늘의 기온을 다음 날 기온으로 예측하는 경향이 있습니다.
XGboost를 써도 이 문제는 해결되지 않나봅니다.
- 실험 결과 정리
입력자료와 계절성 유무에 따라 여러 가지 실험을 진행하고, 상관계수와 RMSE를 표로 정리했습니다(제일 좋은 성능은 빨강).
| 실험 입력 자료 | 상관계수 | RMSE |
| 평균 기온 | 0.968 | 2.70 |
| 평균 기온, 평균 풍속, 평균 이슬점 온도 | 0.973 | 2.46 |
| 평균기온, 일강수량, 평균 풍속, 평균 이슬점 온도, 평균 상대습도, 평균 현지기압, 평균 전운량, 합계 일사량 | 0.977 | 2.30 |
| [계절성 제거] 평균 기온 | 0.616 | 2.62 |
| [계절성 제거] 평균 기온, 평균 풍속, 평균 이슬점 온도 | 0.672 | 2.42 |
| [계절성 제거] 평균기온, 일강수량, 평균 풍속, 평균 이슬점 온도, 평균 상대습도, 평균 현지기압, 평균 전운량, 합계 일사량 | 0.754 | 2.13 |
입력 변수를 많이 쓸수록 상관계수가 증가하고 RMSE가 감소합니다.
XGboost로 무언가를 예측할 땐 일단 입력 변수가 많을수록 좋은 것 같습니다.
(입력 변수가 너무 많으면 아닐 수도 있을 것 같긴한데 이런 건 연구하시는 분이 알려주실겁니다.)
그런데 선형회귀모델에서는 계절성을 제거하지 않았을 때 상관계수가 0.98에 RMSE는 2.10, 제거시 상관계수 0.78에 RMSE는 2.02여서 XGboost의 성능이 더 떨어지네요...
- 결론 및 다음 방향
선형회귀모델 성능이 XGboost보다 좋다고 결론내리기보단 두 모델의 성능은 비슷하다?
ASOS 자료 말고 다른 자료를 이용해보자